Répartition de charge
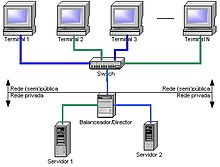
Répartition de charge entre deux serveurs accédés par 4 postes clients, ici le switch et le répartiteur sont deux points de panne potentiels, aucun des deux n'est doublé.
En informatique, la répartition de charge (en anglais : load balancing) est un ensemble de techniques permettant de distribuer une charge de travail entre différents ordinateurs d'un groupe. Ces techniques permettent à la fois de répondre à une charge trop importante d'un service en la répartissant sur plusieurs serveurs, et de réduire l'indisponibilité potentielle de ce service que pourrait provoquer la panne logicielle ou matérielle d'un unique serveur[1],[2].
Ces techniques sont par exemple très utilisées dans le domaine des services HTTP où un site à forte audience doit pouvoir gérer des centaines de milliers de requêtes par seconde.
La répartition de charge est issue de la recherche dans le domaine des ordinateurs parallèles. L'architecture la plus courante est constituée de plusieurs répartiteurs de charge (genres de routeurs dédiés à cette tâche), un principal, et un ou plusieurs de secours pouvant prendre le relais, et d'une collection d'ordinateurs similaires effectuant les calculs. On peut appeler cet ensemble de serveurs une ferme de serveurs (anglais server farm) ou de façon plus générique, une grappe de serveurs (anglais server cluster). On parle encore de server pool (littéralement, « groupe de serveurs »).
Sommaire
1 Terminologie
2 Réglages et paramètres des répartiteurs de charge
3 Les ordinateurs parallèles
4 Les fermes de serveurs
5 La mise en œuvre
6 Principes
6.1 Analyse du risque
7 Partage de charge dans le cadre des réseaux
8 Notes et références
9 Articles connexes
10 Liens externes
Terminologie |
Dans le domaine de la répartition de charge, on appelle :
- « Serveur virtuel », un pool de serveurs affecté à une tâche, l'adresse et le port utilisés doivent être réglés sur le répartiteur de charge et, selon le mode, sur les serveurs de calcul.
- « Serveur réel », un des serveurs dans le pool.
Réglages et paramètres des répartiteurs de charge |
Sur les répartiteurs de charge les plus courants, on peut pondérer la charge de chaque serveur indépendamment. Cela est utile lorsque, par exemple, on veut mettre, à la suite d'un pic ponctuel de charge, un serveur de puissance différente dans la grappe pour alléger sa surcharge. On peut ainsi y ajouter un serveur moins puissant, si cela suffit, ou un serveur plus puissant en adaptant le poids.
Il est généralement également possible de choisir entre plusieurs algorithmes d'ordonnancement :
Round-Robin : C'est l'algorithme le plus simple, une requête est envoyée au premier serveur, puis une au second, et ainsi de suite jusqu'au dernier, puis un tour est recommencé avec une première requête au premier serveur, etc.
- Round-Robin pondéré : Les serveurs de poids fort prennent les premières requêtes et en prennent davantage que ceux de poids faible.
- Moins de connexion : Assigne davantage de requêtes aux serveurs en exécutant le moins.
- Moins de connexion, pondéré : Assigne davantage de requêtes aux serveurs en exécutant le moins en tenant compte de leur poids.
- Hachage de destination : Répartit les requêtes en fonction d'une table de hachage contenant les adresses IP des serveurs.
- Hachage de source : Répartit les requêtes en fonction d'une table de hachage basée sur les adresses IP d'où proviennent les requêtes.
- ...
Il y a deux façons de router les paquets, lors des requêtes :
Network address translation (NAT, traduction d'adresse réseau) : Dans ce cas, le répartiteur reçoit les requêtes, les renvoie aux différents serveurs de calcul en adresse IP privée, reçoit les réponses et les renvoie aux demandeurs. Cette technique est très simple à mettre en place, mais demande au répartiteur d'assumer toute la charge du trafic réseau.- Routage direct (DR, Direct Routing) : Dans ce cas, les requêtes arrivent sur le répartiteur, sont renvoyées aux serveurs de calcul, qui renvoient directement les réponses au demandeur. Cela oblige à monopoliser davantage d'adresses IP (les adresses IPv4 sont limitées et de plus en plus difficiles à obtenir auprès du RIPE), mais allège considérablement le trafic réseau du répartiteur de charge et enlève donc par là-même un goulot d'étranglement. Dans la majorité des cas, pour le HTTP, les requêtes (URL et quelques variables) sont beaucoup plus petites que les réponses, qui sont généralement des fichiers dynamiques (XHTML) produits par un langage de script ou des fichiers statiques (JavaScript, CSS, images, sons, vidéos).
Le protocole Virtual Router Redundancy Protocol (VRRP, protocole de redondance de routeur virtuel), permet de gérer la reprise sur panne d'un des répartiteurs de charge.
Les ordinateurs parallèles |
Un ordinateur parallèle est composé d'un ensemble de dispositifs de calcul qui communiquent et coopèrent dans le but de résoudre efficacement un grand problème. Un procédé peu coûteux est de construire un ordinateur parallèle à l'aide d'une batterie d'unités de calcul, où chaque unité comporte un processeur, une mémoire et une connexion au réseau - des composants disponibles dans le commerce. Le nombre d'unités est choisi en fonction de la grandeur du problème, et peut être modifié par la suite, ce qui assure la scalabilité de l'ensemble[3].
Un programme parallèle est composé d'une suite de processus, où chaque processus exécute une ou plusieurs tâches. La création d'un programme parallèle implique la répartition de la charge, c'est-à-dire la décomposition de l'ensemble du calcul en petites tâches et l'affectation des tâches aux unités[3].
Le but visé par les algorithmes de répartition de charge est d'obtenir une décomposition optimale : que le travail soit réparti de manière équilibrée entre les processeurs, et que les communications entre les différents processeurs soient réduites au minimum. En plus de la répartition des tâches, réalisée avant leur exécution, il existe également des algorithmes visant à déplacer des tâches en cours d'exécution vers un processeur moins occupé[3].
Un algorithme de répartition statique distribue les tâches sur la base de la quantité de travail a priori de chaque tâche. Ce type d'algorithme donne de bons résultats lorsque la durée d'exécution de chaque tâche est prévisible. Un algorithme dynamique vise à obtenir de meilleurs résultats en effectuant continuellement des mesures du taux d'occupation de chaque processeur. Ces mesures peuvent cependant entraîner un ralentissement de l'exécution des tâches[3].
Les fermes de serveurs |

Ferme de serveurs NEC.
Dans une ferme de serveurs (server cluster en anglais) un groupe de serveurs fonctionne comme un dispositif informatique unique. Les machines sont reliées entre elles et exécutent un logiciel qui contrôle leur activité et leur disponibilité, dans le but d'exploiter leur disponibilité par la répartition de charge. Les informations relatives à la disponibilité de chaque machine sont envoyées à un serveur maître, et celui-ci distribue les tâches entre les machines de la ferme en choisissant de préférence celles qui sont le plus disponibles, ceci en vue d'éviter la saturation d'une des machines de la ferme[4].
Les institutions favorisent les fermes de serveurs, en particulier pour les applications internet, parce que celles-ci permettent
d'assurer une haute disponibilité de l'application, ainsi qu'une scalabilité élevée : la croissance peut être prise en charge dans une très large mesure par l'adaptation du matériel[4]. La popularisation d'Internet dans les années 1990 a permis pour la première fois de mettre des services à disposition du monde entier, et l'équilibrage de charge a permis à ces services de supporter de manière sûre, fiable et rapide des demandes provenant de plusieurs millions d'utilisateurs[1].
Selon une étude parue en 2003, le moteur de recherche Google est une ferme de serveurs composée de 6 000 micro-ordinateurs, qui peut répondre à 1000 demandes de recherche par seconde. De la même manière, tous les services Internet populaires utilisent à l'insu du client une batterie d'ordinateurs, et la technique de l'équilibrage de charge[1].
La mise en œuvre |
La répartition de charge permet de distribuer des applications à travers un réseau. Cette technique permet de distribuer n'importe quel service entre différents ordinateurs et emplacements géographiques. Elle est principalement utilisée pour les serveurs web, ainsi que les points d'accès VPN, les proxy ou les pare-feu[5],[6].
La visite d'un site web provoque l'émission de requêtes HTTP. Chaque requête contient le nom du serveur à qui elle est destinée, qui devra alors la traiter. Le travail du serveur peut être allégé en envoyant les requêtes suivantes à d'autres serveurs à tour de rôle[5]. Une technique consiste à faire correspondre le nom du serveur avec plusieurs ordinateurs en modifiant continuellement les tables de correspondance du service DNS. La distribution par le DNS ne tient cependant pas compte de l'état des serveurs, en particulier de la disponibilité et des pannes éventuelles. Les demandes peuvent alors être envoyées à des serveurs qui sont déjà 100 % occupés, ou à des serveurs en panne. L'utilisation d'un dispositif de répartition permet de résoudre ces deux problèmes[5],[6].
Le répartiteur peut être un routeur, un switch, un système d'exploitation ou un logiciel applicatif. Il répartit les demandes en les distribuant uniquement aux serveurs disponibles. Le destinataire des demandes peut également être imposé : dans un site de vente en ligne, lorsqu'une demande sécurisée est faite par un acheteur - par exemple l'achat d'un produit - les demandes suivantes provenant de cet acheteur seront toutes envoyées au même serveur[5],[6]. Le répartiteur simule la présence d'un serveur : les clients communiquent avec le répartiteur comme s'il s'agissait d'un serveur. Celui-ci répartit les demandes provenant des clients et les transmet aux différents serveurs. Lorsqu'un serveur répond à une demande, celle-ci est transmise au répartiteur ; puis le répartiteur transmet la réponse au client en modifiant l'adresse IP de l'expéditeur pour faire comme si cette réponse provenait du serveur[6].
Les machines de la ferme doivent avoir accès au même lot de fichiers, ceci peut être réalisé à l'aide d'un système de fichiers distribué ou à l'aide d'un réseau de stockage (abr. SAN). Les serveurs ne vérifient pas individuellement les sessions parce que, du fait de la répartition, plusieurs serveurs peuvent être impliqués lors d'une même session[5].
Principes |
Analyse du risque |
Si de gros volumes de données sont concernés il sera difficile de tout sauvegarder sans mettre en place de grosses unités de sauvegarde et de bande passante. La perte de données doit être envisagée afin de choisir celles dont l'impact est fort (sauvegardes importantes) ou faible (données transitoires). Par exemple, pour un site marchand, perdre le contenu d'un panier est bien plus dommageable que la liste des articles que l'internaute vient de visiter.
Un autre indicateur important consiste à estimer le temps d'indisponibilité toléré sur un an en pourcentage. On le quantifie en « nombre de neuf ».
- 99 % de disponibilité : moins de 3,65 jours hors service tolérés par an
- 99,9 % : moins de 8,75 heures
- 99,999 % : moins de 5,2 minutes (référence dans le monde des télécommunications)
Partage de charge dans le cadre des réseaux |
Le principe de la répartition de charge s'applique aussi au domaine des connexions réseau. Il existe plusieurs façons de mettre en place ce type de solution. On peut soit acheter un boîtier d'équilibrage de charge et l'administrer soi-même ; soit, comme certaines entreprises le proposent : acquérir le boîtier et faire appel au service de supervision qui l'accompagne.
Des constructeurs équipementiers ont conçu des boîtiers de partage de charge.
Ces dernières années[Quand ?], des sociétés ont développé des services complets de répartition de charge dans le domaine des réseaux et connexions Internet.
Notes et références |
(en) Hossein Bidgoli,The Internet encyclopedia, Volume 1,John Wiley and Sons - 2004, (ISBN 9780471222026)
(en) Joseph Hellerstein - Yixin Diao - Sujay Parekh - Dawn M. Tilbury,Feedback control of computing systems,John Wiley & Sons - 2004, (ISBN 9780471266372)
(en) Chengzhong Xu - Francis C. M. Lau,Load balancing in parallel computers: theory and practice,Springer - 1997, (ISBN 9780792398196)
(en) Nathan J. Muller,Network manager's handbook,McGraw-Hill Professional - 2002, (ISBN 9780071405676)
(en) Charles Bookman,Linux clustering: building and maintaining Linux clusters,Sams Publishing - 2003, (ISBN 9781578702749)
(en) Mauricio Arregoces - Maurizio Portolani,Data center fundamentals,Cisco Press - 2003, (ISBN 9781587050237)
Articles connexes |
- Round-robin
Shortest Path Bridging (IEEE 802.1aq)- CARP
- Virtual Router Redundancy Protocol
HAProxy (en), logiciel libre de répartition de charge
Linux Virtual Server, solution de répartition de charge open-source pour Linux.
IPVS, répartiteur de charge du noyau linux.
RAID, répartition au niveau des disques durs- Grappe de serveurs
- Edge computing
Liens externes |
(en) Making applications scalable with Load Balancing
(fr) Portail français du Load Balancing
(fr) Portail d'information sur le Load Balancing
 Portail de l’informatique
Portail de l’informatique  Portail de la sécurité informatique
Portail de la sécurité informatique


